Chunk-based processing¶
As mentioned in the previous section, the framework is designed to be compatible with chunk-based processing. As opposed to “batch processing”, where the entire input signal is known a priori, this means working with consecutive chunks of input signals of arbitrary size. In practice the chunk size will often be the same from one chunk to another. However, this is not a requirement here, and the framework can accept input chunks of varying size.
The main constraint behind working with an input that is segmented into chunks is that the returned output should be exactly the same as if the whole input signal (i.e., the concatenated chunks) was used as input. In other terms, the transition from one chunk to the next needs to be taken into account in the processing. For example, concatenating the outputs obtained from a simple filter applied separately to two consecutive chunks will not provide the same output as if the concatenated chunks were used as input. To obtain the same output, one should for example use methods such as overlap-add or overlap-save. This is not trivial, particularly in the context of the Auditory front-end where more complex operations than simple filtering are involved. A general description of the method used to ensure chunk-based processing is given in processChunk method and chunk-based compatibility.
Handling segmented input in practice is done mostly the same way as for a whole
input signal. The available demo script DEMO_ChunkBased.m provides an
example of chunk-based processing by simulating a chunk-based acquisition of the
input signal with variable chunk size and computing the corresponding ILDs.
In this script, one can note the two differences in using the Auditory front-end in a chunk-based scenario, in comparison to a batch scenario:
21 22 23 | % Instantiation of data and manager objects
dataObj = dataObject([],fsHz,10,2);
managerObj = manager(dataObj);
|
Because the signal is not known before the processing is carried out, the data
object cannot be initialised from the input signal. Hence, as is seen on line
22, one needs to instantiate an empty data object, by leaving the first input
argument blank. The sampling frequency is still necessary however. The third
argument (here set to 10) is a global signal buffer size in seconds. Because
in an online scenario, the framework could be operating over a long period of
time, internal representations cannot be stored over the whole duration and are
instead kept for the duration mentioned there. The last argument (2)
indicates the number of channel that the framework should expect from the input
(a mono input would have been indicated by 1). Again, it is necessary to
know the number of channels in the input signal, to instantiate the necessary
objects in the data object and the manager.
43 44 | % Request the processing of the chunk
managerObj.processChunk(sIn(chunkStart:chunkStop,:),1);
|
The processing is carried out on line 44 by calling the processChunk method
of the manager. This method takes as input argument the new chunk of input
signal. The additional argument, 1, indicates that the results should be
appended to the internal representations already computed. This can be set to
0 in cases where keeping track of the output for the previous chunks is
unnecessary, for instance if the output of the current chunk is used by a
higher-level function. The difference with the processSignal method is
important. Although processSignal actually calls internally
processChunk, it also resets internal states of the framework (what ensures
continuity between chunks) before processing.
The script DEMO_ChunkBased.m will also compute the offline result and will
plot the difference in output for the two computations. This plot is shown in
Fig. 15. Note the magnitude on the order of
\(10^{-15}\), which is in the range of Matlab numerical precision,
suggesting that the representations computed online or offline are the same up
to some round-off errors.
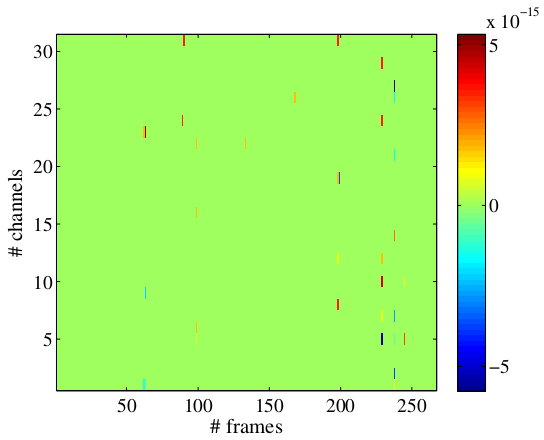
Fig. 15 Difference in ILDs obtained with online and offline processing