Segmentation with and without priming¶
The Blackboard system of the Two!Ears Auditory Model is equipped with a SegmentationKS
knowledge source which is capable of generating soft-masks for auditory features
in the time-frequency domain. The segmentation framework relies on a
probabilistic clustering approach to assign individual time-frequency units to
sound sources that are present in the scene. This assignment can either be
computed unsupervised or exploit additional prior knowledge about potential
source positions provided by the user or e.g. by the DnnLocationKS knowledge
source.
Note
To run the examples, an instance of the SegmentationKS knowledge source
has to be trained first. Please refer to
(Re)train the segmentation stage for details.
This example will demonstrate how the SegmentationKS knowledge source is
properly initialised with and without prior knowledge and how the hypotheses
which are generated by the segmentation framwork can be used within the
Blackboard system. The example can be found in the examples/segmentation folder
which consists of the following files:
demo_segmentation_clean.m
demo_segmentation_noisy.m
demo_segmentation_priming.m
demo_train_segmentation.m
segmentation_blackboard_clean.xml
segmentation_blackboard_noise.xml
segmentation_config.xml
test_scene_clean.xml
test_scene_noise.xml
training_scene.xml
Note
The SegmentationKS knowledge source is based on Matlab functions that
were introduced in release R2013b. Therefore, it is currently not possible
to use SegmentationKS with earlier versions of Matlab.
The example contains three different demo scenes, namely
demo_segmentation_clean.m, demo_segmentation_noisy.m and
demo_segmentation_priming.m. The first demo shows the segmentation framework
for three speakers in anechoic and undisturbed acoustic conditions without
providing prior knowledge about the speaker positions. The scene parameters are
specified in the corresponding test_scene_clean.xml file:
<?xml version="1.0" encoding="utf-8"?>
<scene
Renderer="ssr_binaural"
BlockSize="4096"
SampleRate="44100"
LengthOfSimulation = "3"
HRIRs="impulse_responses/qu_kemar_anechoic/QU_KEMAR_anechoic_3m.sofa">
<source Name="Speaker1"
Type="point"
Position="0.8660 0.5 1.75">
<buffer ChannelMapping="1"
Type="fifo"
File="sound_databases/IEEE_AASP/speech/speech08.wav"/>
</source>
<source Name="Speaker2"
Type="point"
Position="1 0 1.75">
<buffer ChannelMapping="1"
Type="fifo"
File="sound_databases/IEEE_AASP/speech/speech14.wav"/>
</source>
<source Name="Speaker3"
Type="point"
Position="0.8660 -0.5 1.75">
<buffer ChannelMapping="1"
Type="fifo"
File="sound_databases/IEEE_AASP/speech/speech07.wav"/>
</source>
<sink Name="Head"
Position="0 0 1.75"
UnitX="1 0 0"
UnitZ="0 0 1"/>
</scene>
The speaker positions described here correspond to angular positions at -30°, 0°
and 30°, respectively. These positions will be fixed for all conditions in this
demo. For more documentation on specifying an acoustic scene, see
Configuration using XML Scene Description. Additionally, the file
segmentation_blackboard_clean.xml contains the necessary information to
build a Blackboard system with the corresponding SegmentationKS (see
Setting up the blackboard for details):
<?xml version="1.0" encoding="utf-8"?>
<blackboardsystem>
<dataConnection Type="AuditoryFrontEndKS"/>
<KS Name="seg" Type="SegmentationKS">
<Param Type="char">DemoKS</Param>
<Param Type="double">3</Param>
<Param Type="int">3</Param>
<Param Type="int">0</Param>
</KS>
<Connection Mode="replaceOld" Event="AgendaEmpty">
<source>scheduler</source>
<sink>dataConnect</sink>
</Connection>
<Connection Mode="replaceOld">
<source>dataConnect</source>
<sink>seg</sink>
</Connection>
</blackboardsystem>
The SegmentationKS knowledge source takes four parameters as input
arguments. The first parameter is the name of the knowledge source instance
which contains previously trained localisation models. For further information
about training this specific knowledge source, please refer to
(Re)train the segmentation stage. The second parameter defines the
block size in seconds on which the segmentation should be performed. In this
demo, a block size of 3 seconds is assumed for all cases. The third parameter
specifies the number of sources which are assumed to be present in a scene and
the fourth parameter is a flag which can be either set to 0 or 1, indicating if
an additional background estimation should be performed. If this is the case,
the model assumes that individual time-frequency units can either be associated
with a sound source or with background noise, which is helpful in noisy acoustic
environments but can also degrade performance if no or little background noise
is present. As no background noise is assumed in the first demo, this parameter
is set to zero accordingly. Running the script demo_segmentation_clean.m
will produce a result similar to Fig. Fig. 48.
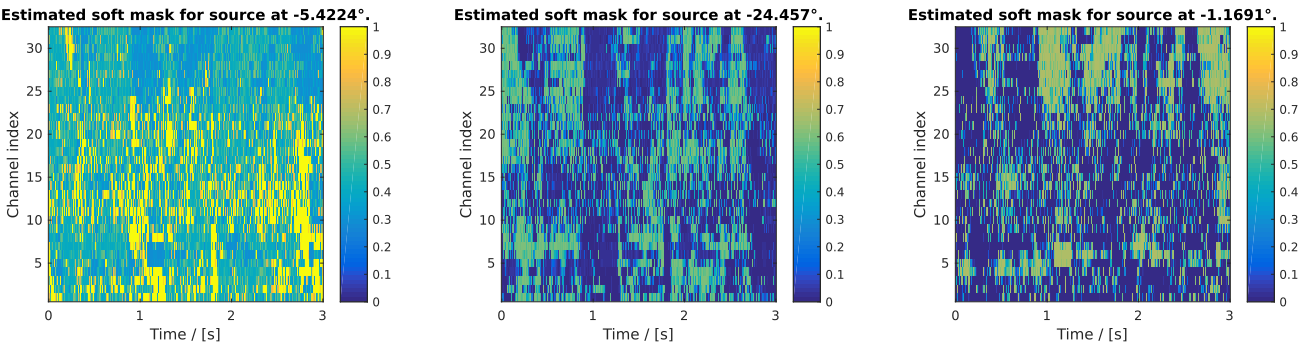
Fig. 48 Figure generated after running the script demo_segmentation_clean.m.
The figure shows all three soft masks and location estimates for the speech
sources that are simulated in this demo. Note that the estimated positions do
not necessarily match the true positions (-30°, 0° and 30°) due to the
limited localisation capabilities of the SegmentationKS knowledge source.
This problem can be circumvented by exploiting prior knowledge about the
source positions (see below).
The second demo file demo_segmentation_noisy.m provides essentially the same
acoustic configuration as the first demo with additional diffuse background
noise. This is specified in the corresponding test_scene_noise.xml
configuration file:
<?xml version="1.0" encoding="utf-8"?>
<scene
Renderer="ssr_binaural"
BlockSize="4096"
SampleRate="44100"
LengthOfSimulation = "3"
HRIRs="impulse_responses/qu_kemar_anechoic/QU_KEMAR_anechoic_3m.sofa">
<source Name="Speaker1"
Type="point"
Position="0.8660 0.5 1.75">
<buffer ChannelMapping="1"
Type="fifo"
File="sound_databases/IEEE_AASP/speech/speech08.wav"/>
</source>
<source Name="Speaker2"
Type="point"
Position="1 0 1.75">
<buffer ChannelMapping="1"
Type="fifo"
File="sound_databases/IEEE_AASP/speech/speech14.wav"/>
</source>
<source Name="Speaker3"
Type="point"
Position="0.8660 -0.5 1.75">
<buffer ChannelMapping="1"
Type="fifo"
File="sound_databases/IEEE_AASP/speech/speech07.wav"/>
</source>
<source Type="pwd"
Name="Noise"
Azimuths="0 30 60 90 120 150 180 210 240 270 300 330">
<buffer ChannelMapping="1 2 3 4 5 6 7 8 9 10 11 12"
Type="noise"
Variance="0.02"
Mean="0.0"/>
</source>
<sink Name="Head"
Position="0 0 1.75"
UnitX="1 0 0"
UnitZ="0 0 1"/>
</scene>
To account for the background noise during the estimation process, the
corresponding flag in the blackboard configuration file
segmentation_blackboard_noise.xml is set to one:
<?xml version="1.0" encoding="utf-8"?>
<blackboardsystem>
<dataConnection Type="AuditoryFrontEndKS"/>
<KS Name="seg" Type="SegmentationKS">
<Param Type="char">DemoKS</Param>
<Param Type="double">3</Param>
<Param Type="int">3</Param>
<Param Type="int">1</Param>
</KS>
<Connection Mode="replaceOld" Event="AgendaEmpty">
<source>scheduler</source>
<sink>dataConnect</sink>
</Connection>
<Connection Mode="replaceOld">
<source>dataConnect</source>
<sink>seg</sink>
</Connection>
</blackboardsystem>
Running the corresponding script demo_segmentation_noisy.m will generate
an additional soft-mask for the background noise which is shown in Fig.
Fig. 49.
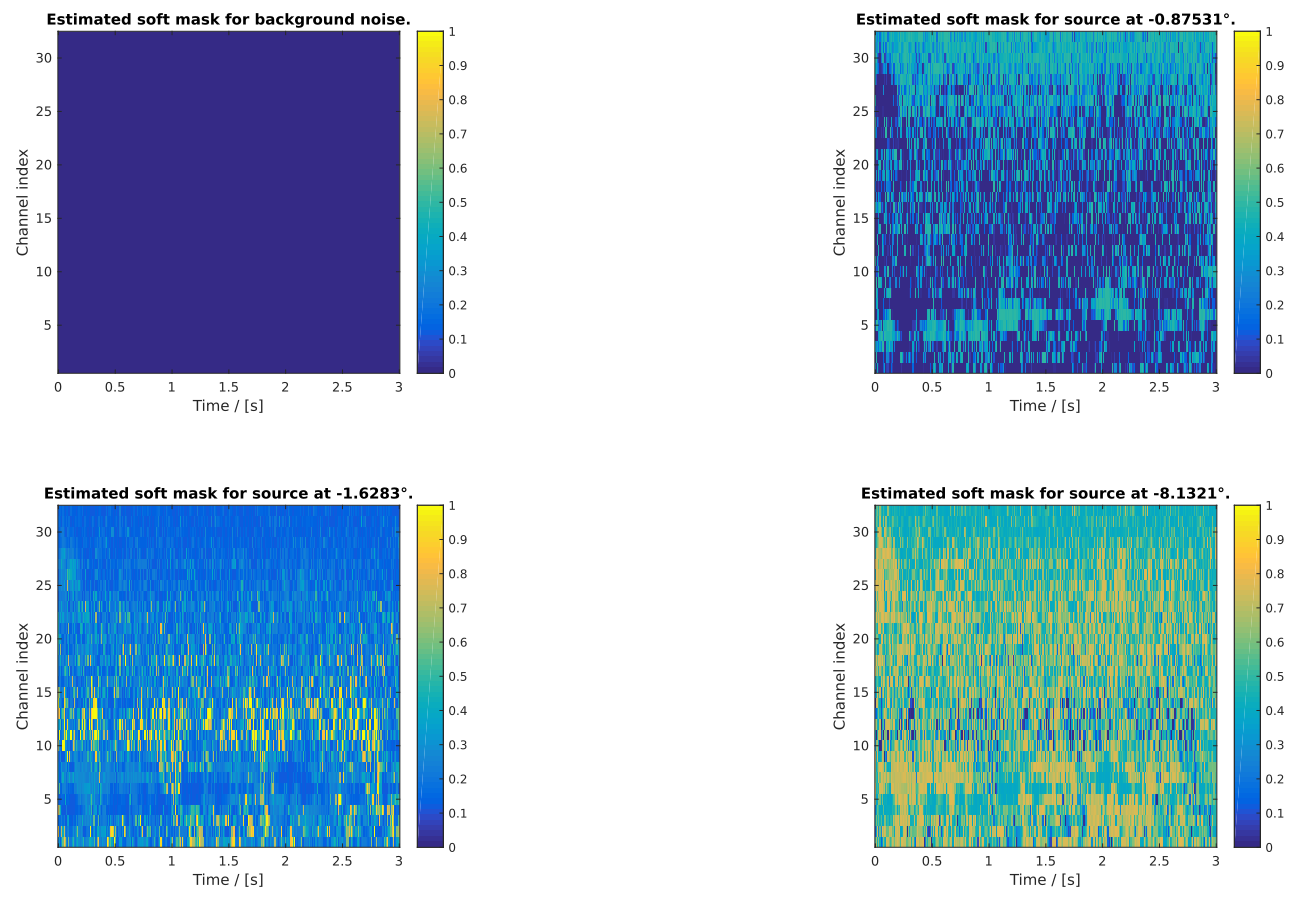
Fig. 49 Figure generated after running the script demo_segmentation_noisy.m.
The figure shows four soft masks of which three correspond to the individual
sources and the remaining one is a soft-mask for the background noise. Note
that the latter one only contains very small probabilities for all
time-frequency units in this demo. This is due to the fact that stationary
white noise was used in this case and the (partially overlapping) speech
sources cover a broad range of the whole time-frequency spectrum.
Note
The background noise estimation procedure is based on the assumption that the noise present in the scene is diffuse and hence its directions of arrival follow a uniform distribution around the unit circle. If this condition is not valid and directional noise sources are present, considering them as additional sources instead of using the background estimation procedure might yield better results.
Finally, the third demo shows the possibilities of priming the
SegmentationKS knowledge source, which means providing prior knowledge about
the source positions before the segmentation is actually performed. For this
purpose, the implementation of SegmentationKS provides an additional
function setFixedPositions() which can be used to manually specify the
positions of the sound sources. In the script
demo_segmentation_priming.m, this is done in the following way:
1 2 3 | % Provide prior knowledge of the two speaker locations
prior = [-deg2rad(30); deg2rad(30); 0];
bbs.blackboard.KSs{2}.setFixedPositions(prior);
|
It is also possible to exploit this functionality dynamically during runtime by
using intermediate results of the DnnLocationKS knowledge source from the
blackboard. Note that angular positions are handled in radians within the
SegmentationKS framework, hence position estimates in degrees must be
converted accordingly. A possible result for this demo is shown in Fig.
Fig. 50.
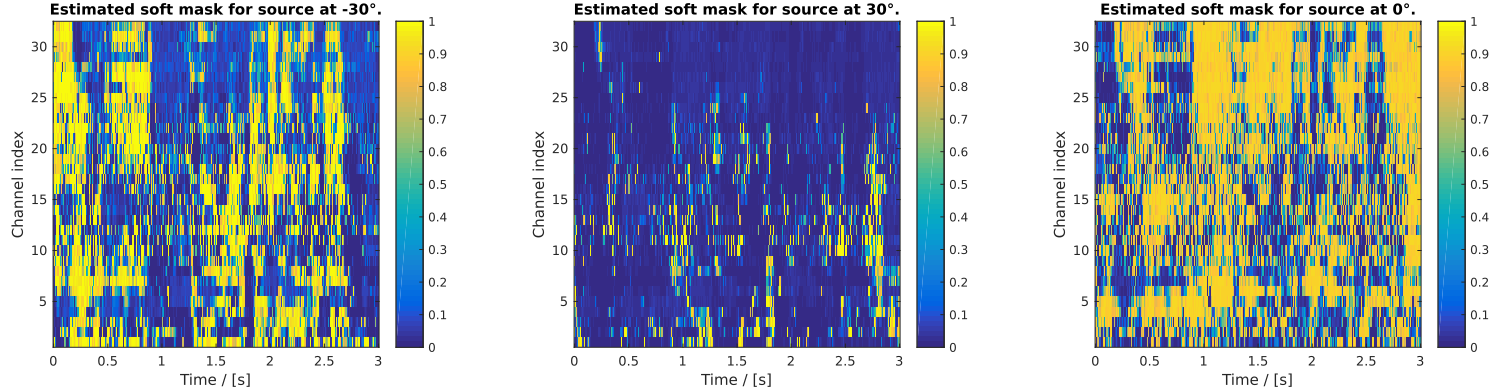
Fig. 50 Figure generated after running the script demo_segmentation_priming.m.