Overview of the architecture¶
The Two!Ears computational framework of auditory perception and experience entails low-level audio processing, high-level feature extraction and reasoning, and includes various sorts of feedbacks. Such an architecture actually relies on three layers in the deployment system, see Fig. 6:
the functional layer, which is composed of software components which can run concurrently under severe time and communication constraints. These are in charge of sensorimotor functions, such as locomotion, proprioceptive or exteroceptive data acquisition and processing, obstacle avoidance, reactive navigation, localization, etc. Most of these functionalities are handled by corresponding ROS nodes, which are possibly connected to each others to transmit data, control orders, state flags, etc. genomix and rosix servers are also part of this functional layer, and can both receive HTTP GET requests from higher layers for controlling respectively GenoM3 and ROS components, and reading their data flows.
the hardware layer, which is mainly composed of hardware components in charge of specific functionalities. One can list for instance:
- cameras, in charge of collecting images;
- an audio acquisition board, in charge of the sampling of audio data;
- the neck motor controller, in charge of moving the KEMAR head on the deployment system;
- the mobile platform itself (Jido @LAAS or ODI @ISIR).
Importantly, each of these components have dedicated ROS node(s) which are used to interface the hardware with the functional level through drivers provided by the operating system. So, a
/cameraROS nodes communicates with the camera on the robot, the/bassROS/GenoM3 node/module is in charge of collecting audio samples from the audio device, etc.the decisional layer, which hosts deliberation primitives (learning, goal reasoning, task planning, deliberate action/perception and monitoring). These abilities take place at a more abstract level, under lighter time constraints, and most of them rely on an Matlab implementation.
The genuine auditory front-end is placed between the functional and decisional layers, and bridges the gap between low-level signal driven considerations and higher-level representations. The ROS implementation of the Auditory front-end will now entirely rely on the functional level, the higher-level signal representations being now computed with real-time constraints. Consequently, these representations have now to be transmitted to the decisional layer through adequate strategies. Thus, the ROS implementation of the auditory front end is based on:
- a C/C++ library
openAFE, which actually implements the core algorithmic functionalities needed by the ROS implementation of the Auditory front-end, - a ROS/GenoM3 node/module
/rosAFE, which implements the Auditory front-end processors, handles concurrency between them, and defines standard interface to transmit the computed audio descriptions to other ROS nodes or to higher levels in the architecture, - a Matlab client to
/rosAFE, which communicates with the ROS nodes/rosAFEthanks to thematlab-genomixbridge.
Their installation and use is depicted in the following.
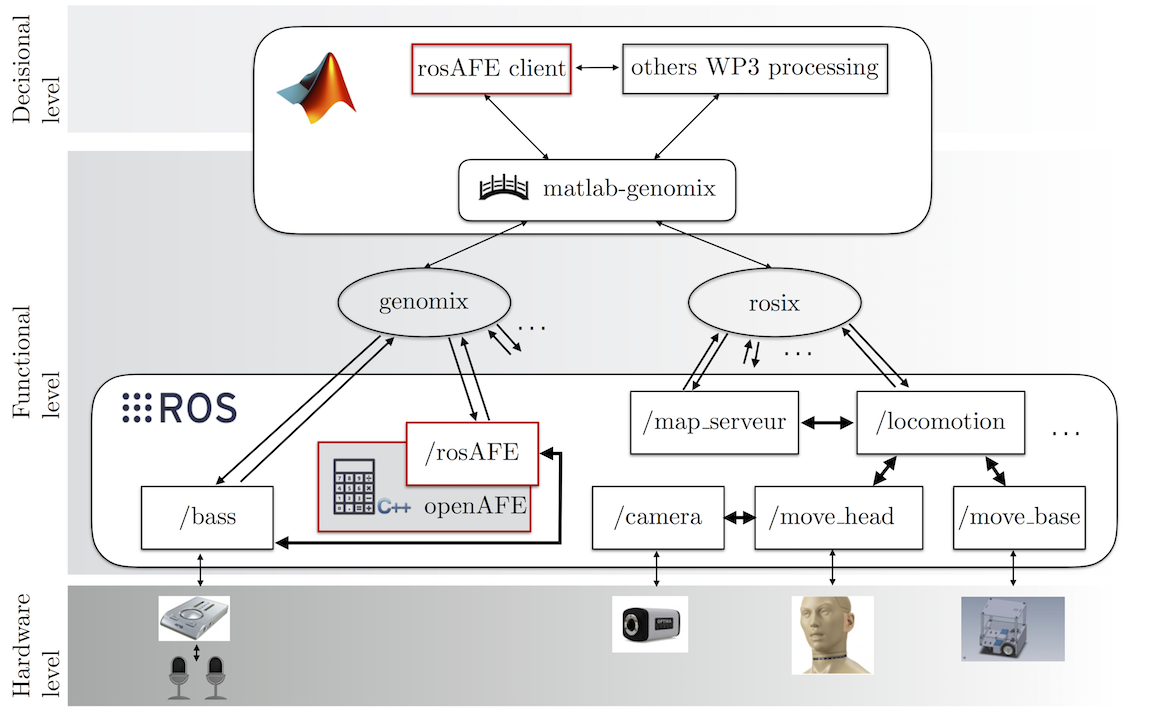
Fig. 6 Overview of the architecture.