Localisation¶
2012-03-01: Localisation of a real vs. binaural simulated point source¶
 Published by members of the Two!Ears consortium
Published by members of the Two!Ears consortium
Digital Object Identifier¶
Description¶
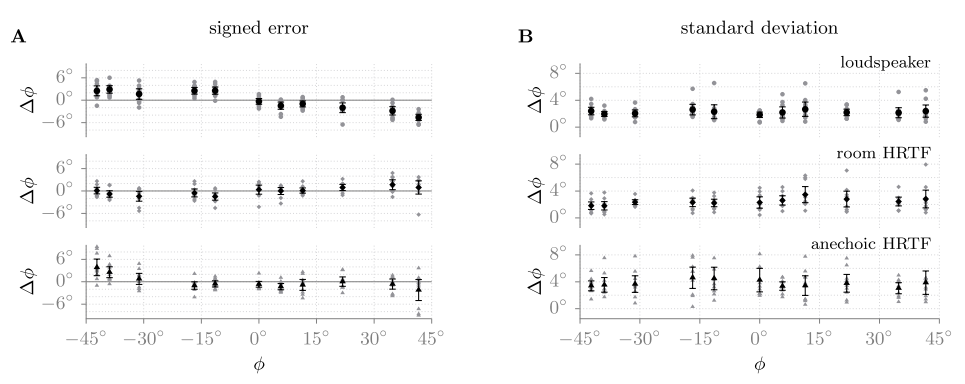
Fig. 45 The mean over all subjects together with the 95% confidence interval is shown. In grey, the individual subjects’ results are presented. In graph A, the signed error of the localization of the eleven speakers is shown. In graph B, the mean standard deviation for the localization task is depicted. The top row represents the condition with the real loudspeakers, the middle row the room HRTFs (BRIRs), and the bottom row the anechoic HRTFs. Figure from [Wierstorf2012].
In this experiment the localisation of a real point source realised by a loudspeaker was compared to the localisation of a binaural simulation of the same source using HRTFs or BRIRs. The results are published in [Wierstorf2012].
Files¶
The BRS files for every loudspeaker are generated by using the BRIRs from TU Berlin, room Calypso, 19-channel linear loudspeaker array and HRTFs from Anechoic HRTFs from the KEMAR manikin with different distances are available under:
experiments/2012-03-01_brs_vs_real_localisation/brs/*
The white noise pulse train under:
experiments/2012-03-01_brs_vs_real_localisation/stimulus/white_noise_pulse.wav
The results of the 11 listeners for the localisation task and of their head movements while performing this task are available under:
experiments/2012-03-01_brs_vs_real_localisation/results/*
experiments/2012-03-01_brs_vs_real_localisation/results_head_movements/*
An analysis of the results including a plotting script and the average results are available at:
experiments/2012-03-01_brs_vs_real_localisation/analysis/*
experiments/2012-03-01_brs_vs_real_localisation/analysis/data_mean/localisation_real_vs_hrir.csv
experiments/2012-03-01_brs_vs_real_localisation/analysis/data_mean/localisation_real_vs_brir.csv
| [Wierstorf2012] | Wierstorf, H., Spors, S., Raake, A. (2012), “Perception and evaluation of sound fields,” 59th Open Seminar on Acoustics, p. 263-68 |
2013-11-01: Localisation of different source types in sound field synthesis¶
Published by members of the Two!Ears consortium
Digital Object Identifier¶
- BRS files: 10.5281/zenodo.55427
- Head movements: 10.5281/zenodo.164620
- Results: 10.5281/zenodo.55439
Description¶

Fig. 46 Average localization results. The black symbols indicate loudspeakers, the grey ones the synthesised source. At every listening position, an arrow is pointing into the direction from which the listeners perceived the corresponding auditory event. The color of the arrow displays the absolute localization error, which is also summarised as an average beside the arrows for every row of positions. The average confidence interval for all localization results is 2.3°. Listening conditions which resulted in listeners saying that they perceived two sources are highlighted with a small 2 written below the position. Figure from [Wierstorf2014b].
In this experiment different sound sources like a point source or plane wave were synthesised using WFS and NFC-HOA. In a series of listening test participants had to localise those sources from different listening positions in order to investigate how well the different methods were able to provide the correct directional impression. In order to compare different systems and different listening positions the experiments were performed with dynamic binaural synthesis. The experiment is described in [Wierstorf2014b].
Files¶
The BRS files for the different conditions and the used noise stimulus can be found under:
experiments/2013-11-01_sfs_localisation/brs/*
experiments/2013-11-01_sfs_localisation/stimulus/white_noise_pulse.wav
The localisation results of the single listeners can be found in the following folders:
experiments/2013-11-01_sfs_localisation/results/nfchoa_ps_circular/*
experiments/2013-11-01_sfs_localisation/results/nfchoa_pw_circular/*
experiments/2013-11-01_sfs_localisation/results/wfs_fs_circular/*
experiments/2013-11-01_sfs_localisation/results/wfs_ps_circular/*
experiments/2013-11-01_sfs_localisation/results/wfs_ps_linear/*
experiments/2013-11-01_sfs_localisation/results/wfs_pw_circular/*
The results are encoded as follows in the csv files:
trial_numberposition in the experiment of the presented condition mode0=> real single loudspeaker (for calibration); otherwise number of used loudspeakers (1456 denotes NFC-HOA with 14 loudspeakers, but an order of 28)sourceinternal number of presented condition nnumber of head-tracker (always 1) xx position of listener (as reported by head-tracker) yy-position of listener zz-position of listener phihorizontal direction of auditory event (includes offset [1]) real_phidirection of virtual sound event (includes offset [1]) deltamedian direction of auditory event [2] stdevstandard deviation of the listener head orientation during acquisition of head-tracking data (nine samples after the person presses enter) elapsed_timetime the person needed to localize the source and press enter
In addition, we provide the trajectory of the actual head movements, each listener performed during the localisation experiments in the following folders:
experiments/2013-11-01_sfs_localisation/results_head_movements/nfchoa_ps_circular/*
experiments/2013-11-01_sfs_localisation/results_head_movements/nfchoa_pw_circular/*
experiments/2013-11-01_sfs_localisation/results_head_movements/wfs_fs_circular/*
experiments/2013-11-01_sfs_localisation/results_head_movements/wfs_ps_circular/*
experiments/2013-11-01_sfs_localisation/results_head_movements/wfs_ps_linear/*
experiments/2013-11-01_sfs_localisation/results_head_movements/wfs_pw_circular/*
Average results can be found at:
experiments/2013-11-01_sfs_localisation/analysis/localization_wfs_ps_circular.txt
experiments/2013-11-01_sfs_localisation/analysis/localization_wfs_ps_linear.txt
experiments/2013-11-01_sfs_localisation/analysis/localization_wfs_pw_circular.txt
experiments/2013-11-01_sfs_localisation/analysis/localization_wfs_fs_circular.txt
experiments/2013-11-01_sfs_localisation/analysis/localization_nfchoa_ps_circular.txt
experiments/2013-11-01_sfs_localisation/analysis/localization_nfchoa_pw_circular.txt
The average results are encoded in the following way
conditionname of used BRS file Xx-position of listener Yy-position of listener phidirection of auditory event [3] phi_error(direction virtual sound event) - (direction auditory event) phi_ci95%-confidence interval of phi stdstandard deviation of the five repetitions used to measure phi std_ci95%-confidence interval of std phi_offsetoffset applied to the virtual sound event [4]
| [1] | (1, 2) The offset was varied for the single conditions. Have a look at the average result files for the actual offset values. |
| [2] | The participants were advised to only look into the horizontal plane. |
| [3] | If two values are provided in the form of {2,25}, two auditory events were perceived at those two positions. |
| [4] | This offset was introduced to have a jitter for the virtual sound event
positions, enabling more randomness to the possible source positions. The
results of phi and phi_error are already offset corrected, but not
the directions reported in the results files for the single listeners,
mentioned above |
| [Wierstorf2014b] | Wierstorf, H. (2014), “Perceptual Assessment of Sound Field Synthesis,” PhD-thesis, TU Berlin |
2016-03-11: Localisation of simulatenous talkers by humans and machines¶
Published by members of the Two!Ears consortium
Description¶
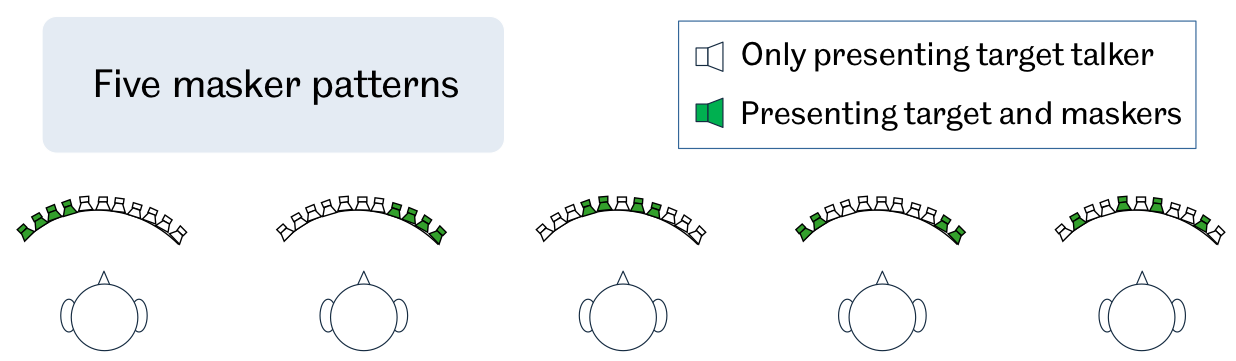
Fig. 47 Experimental settings used in this study. One target female voice and four interfering male voices are presented at the same time from 11 potential loudspeaker locations. Five masker patterns are considered as indicated by the green loudspeakers.
A recent psychophysical study [KopcoEtAl2010] has shown that listeners are able to exploit prior knowledge of the masker locations in a cocktail party scenario. This study investigated the ability of listeners to localise a female target voice in the presence of four male masking voices. The is experimental setup is shown in Fig. 47. In particular, it addresses two main research questions. First, we ask whether listeners are able to exploit prior information about the masker locations in Kopco et al.’s task when listening over headphones, where binaural cues are limited to those present in the HRIRs used to spatialise the signals for headphone listening. In headphone listening, head movements are not available and room characteristics can be carefully controlled; hence, we also investigate whether prior knowledge of the masker locations can assist localisation in both anechoic and reverberant conditions. The results are shown in Fig. 48, where localisation performance for fixed and varied (mixed) masker locations is compared. Second, we ask whether the sources of knowledge available to listeners in this scenario – speaker characteristics and masker locations – can be successfully exploited in a computational system for sound localisation. More details can be found in [MaBrown2016].
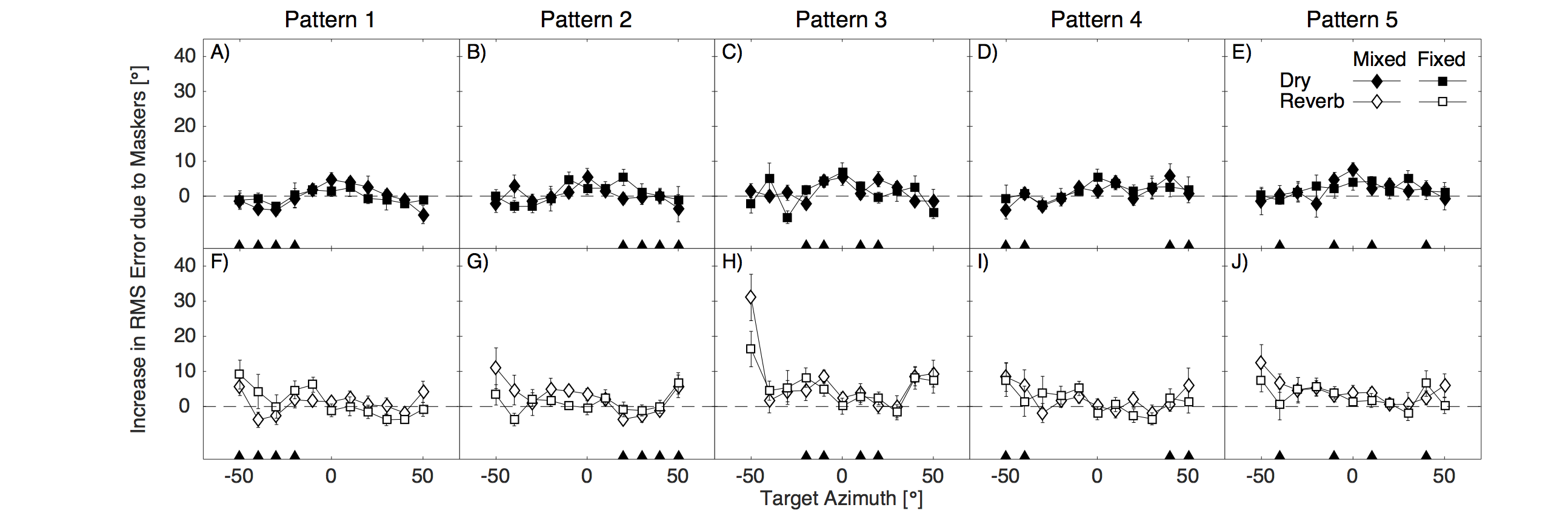
Fig. 48 Across-participant average (\(\pm\) standard error of the mean) of the increases in root-mean-square errors (with respect to the no-masker control condition) as a function of the target location. Masker locations are indicated by the filled triangles along the abscissa. Each column of panels shows the Mixed and Fixed condition data for one masker pattern and for the anechoic session (upper panels) and the reverberant session (lower panels).
Files¶
The results for the individual listeners:
experiments/2016-03-11_kopco/results/*
An analysis of the results including the resulting plots:
experiments/2016-03-11_kopco/analysis/*
experiments/2016-03-11_kopco/analysis/graphics/*
| [KopcoEtAl2010] | Kopco, N., Best, V., and Carlile, S. (2010) “Speech localization in a multitalker mixture,” J. Acoust. Soc. Amer., vol. 127, no. 3, pp. 1450–1457. |
| [MaBrown2016] | Ma, N., Brown, G. (2016) “SSpeech localisation in a multitalker mixture by humans and machines,” In Proceedings of Interspeech 2016, San Francisco, CA. |