Rate-map (ratemapProc.m)
The rate-map represents a map of auditory nerve firing rates [Brown1994] and is
frequently employed as a spectral feature in CASA systems [Wang2006], ASR
[Cooke2001] and speaker identification systems [May2012]. The rate-map is
computed for individual frequency channels by smoothing the IHC signal
representation with a leaky integrator that has a time constant of typically
rm\_decaySec=8 ms. Then, the smoothed IHC signal is averaged across all
samples within a time frame and thus the rate-map can be interpreted as an
auditory spectrogram. Depending on whether the rate-map scaling rm_scaling
has been set to ’magnitude’ or ’power’, either the magnitude or the
squared samples are averaged within each time frame. The temporal resolution can
be adjusted by the window size rm_wSizeSec and the step size
rm_hSizeSec. Moreover, it is possible to control the shape of the window
function rm_wname, which is used to weight the individual samples within a
frame prior to averaging. The default rate-map parameters are listed in
Table 24.
Table 24 List of parameters related to 'ratemap'.
| Parameter |
Default |
Description |
|---|
'rm_wname' |
'hann' |
Window type |
'rm_wSizeSec' |
0.02 |
Window duration in s |
'rm_hSizeSec' |
0.01 |
Window step size in s |
'rm_scaling' |
'power' |
Rate-map scaling ('magnitude' or 'power') |
'rm_decaySec' |
0.008 |
Leaky integrator time constant in s |
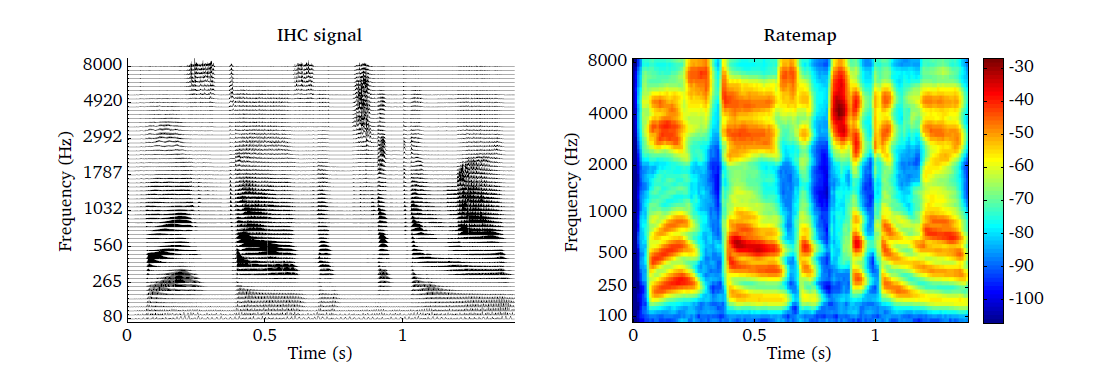
The rate-map is demonstrated by the script DEMO_Ratemap and the
corresponding plots are presented in Fig. 26. The IHC
representation of a speech signal is shown in the left panel, using a bank of 64
gammatone filters spaced between 80 and 8000 Hz. The corresponding rate-map
representation scaled in dB is presented in the right panel.
| [Brown1994] | Brown, G. J. and Cooke, M. P. (1994), “Computational auditory scene
analysis,” Computer Speech and Language 8(4), pp. 297–336. |
| [Cooke2001] | Cooke, M., Green, P., Josifovski, L., and Vizinho, A. (2001), “Robust
automatic speech recognition with missing and unreliable acoustic data,”
Speech Communication 34(3), pp. 267–285. |
| [May2012] | May, T., van de Par, S., and Kohlrausch, A. (2012), “Noise-robust speaker
recognition combining missing data techniques and universal background
modeling,” IEEE Transactions on Audio, Speech, and Language Processing
20(1), pp. 108–121. |
| [Wang2006] | Wang, D. L. and Brown, G. J. (Eds.) (2006), Computational Auditory Scene
Analysis: Principles, Algorithms and Applications, Wiley / IEEE Press. |